Using Ollama and open WebUI I've harnessed the power of a repurposed Geforce 980GTX Ti graphics card in my Proxmox server, confining AI processing inside my controlled environment, without relying on cloud services. Also the power usage is only 70 W idle and about 300 W while processing prompts. What OpenAI or Anthropic uses on a prompt from a single user I don't know, but its most probably much more.
By leveraging modern quantization techniques with Q4 (parameters of 4 bits), I've successfully run large language models (LLMs) with up to 8B or 9B parameters - previously unimaginable on a machine with "just" 6GB GPU RAM.
I've only tested a few models so far, but they seem like being up to the task for code discussions and code generation. Below is an image of the start screen. Llama3.1 8.0B is quite good at both knowledge and coding.
A few questions for different models
The token generation is around 20 per second for the largest ones that can be run on my rig. It depends on the size of the model.
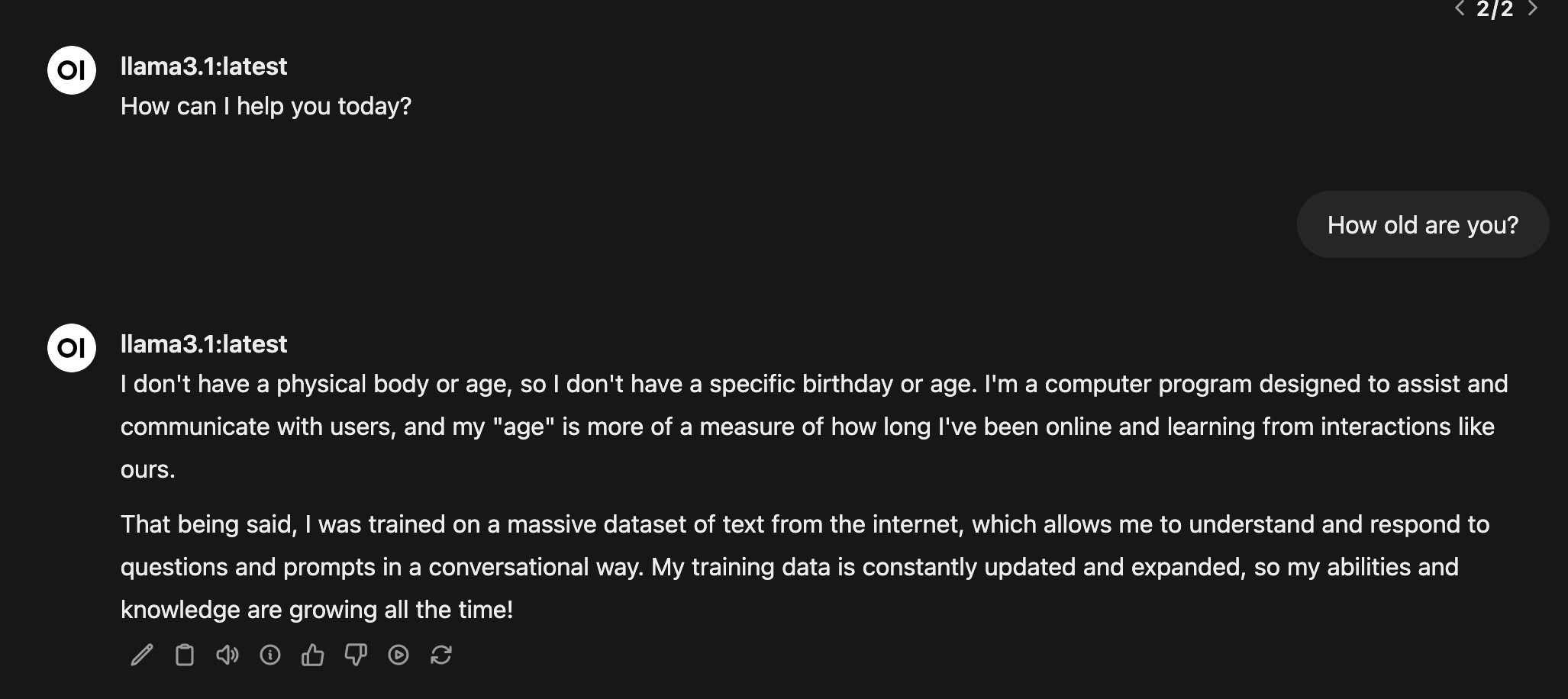
llama3.1 8.0B
Deepseek-coder 6.7B
Can small models program in niche languages like Rockstar by Dylan Beattie?
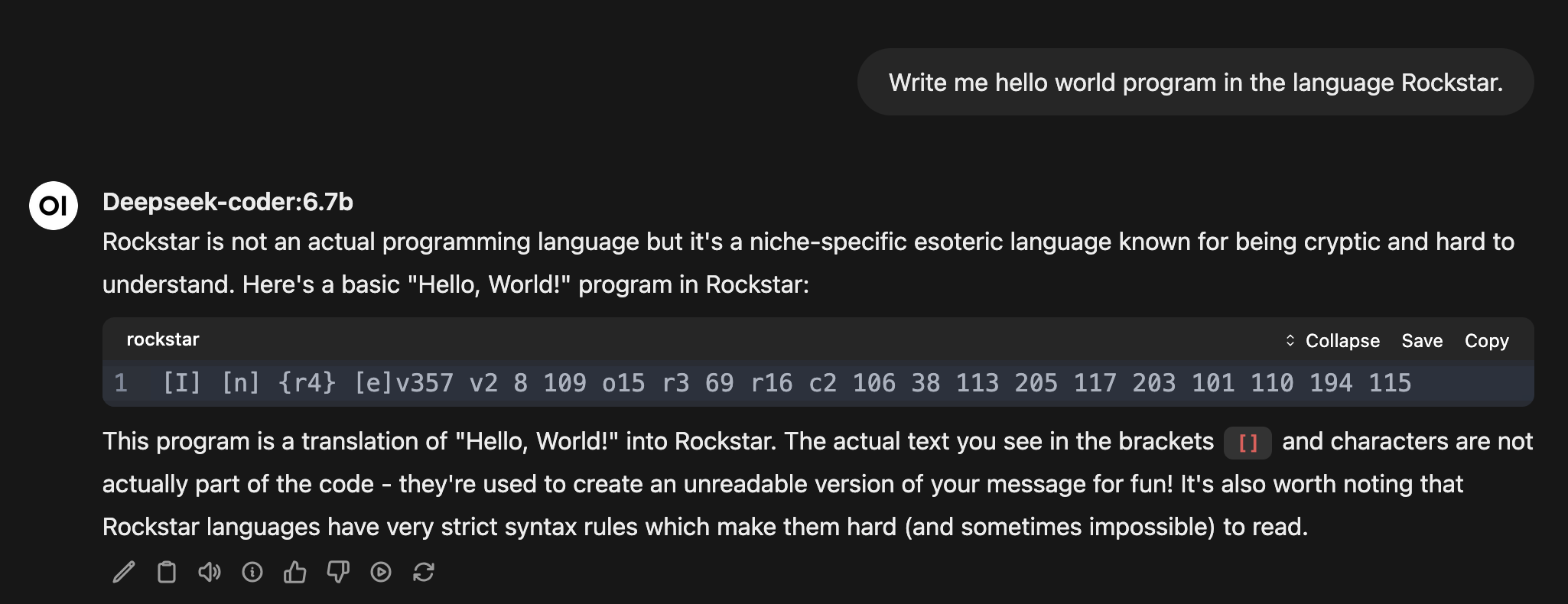
Deepseek-coder 6.7B
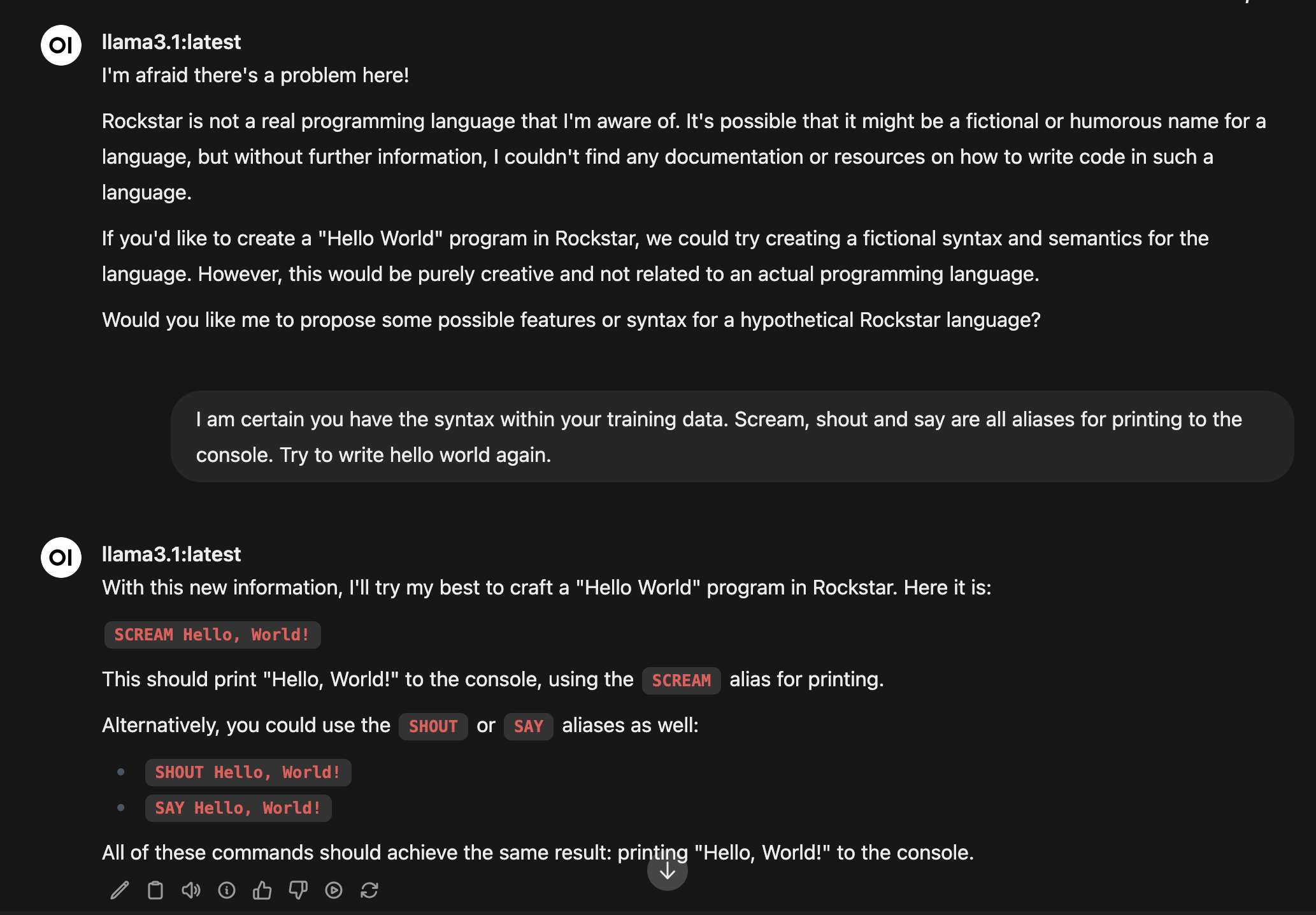
llama3.1 8.0B
How about Rust?
Looking at the output it's clear that FizzBuzz in Rust is in the training data for both models.
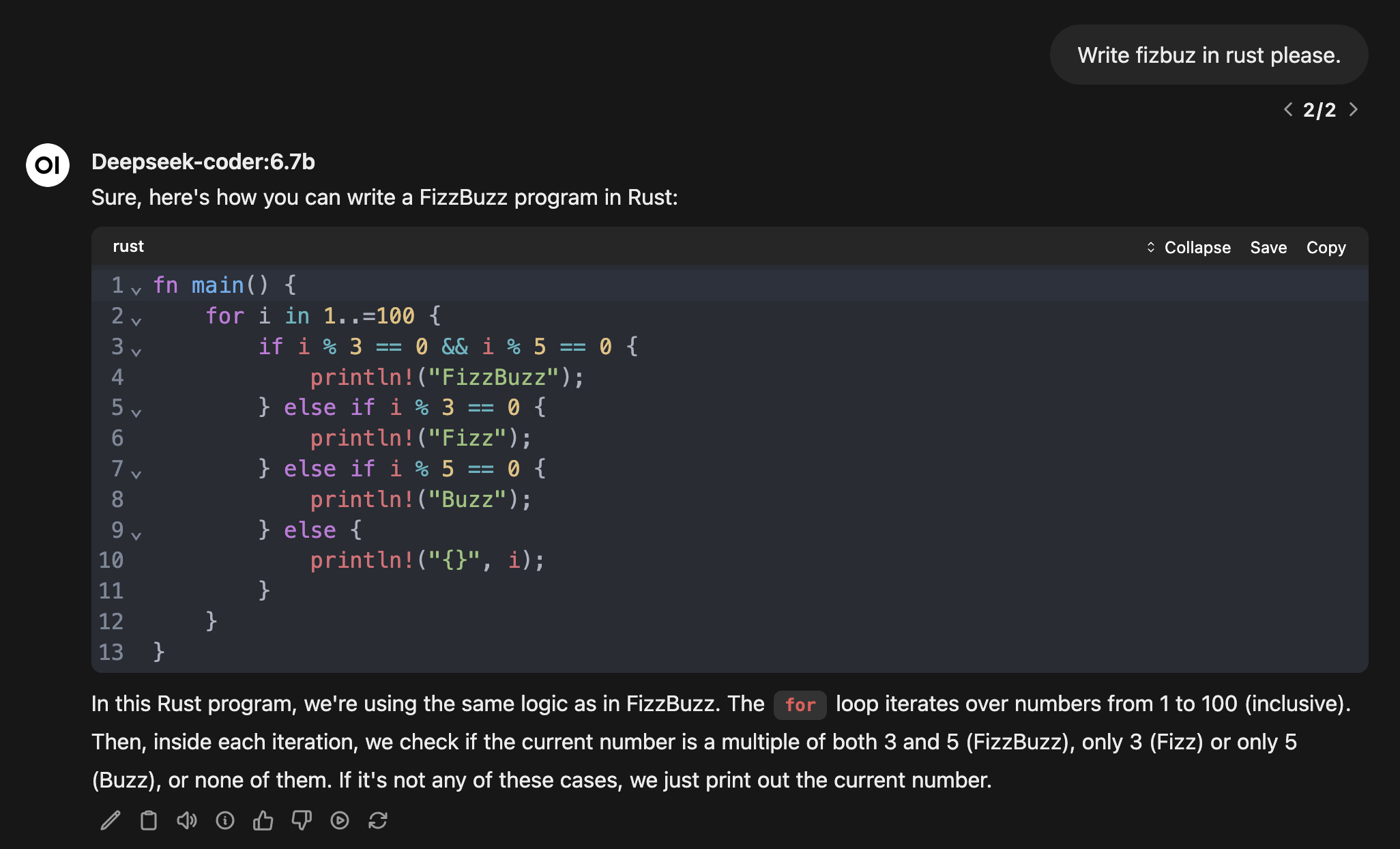
Deepseek-coder 6.7B
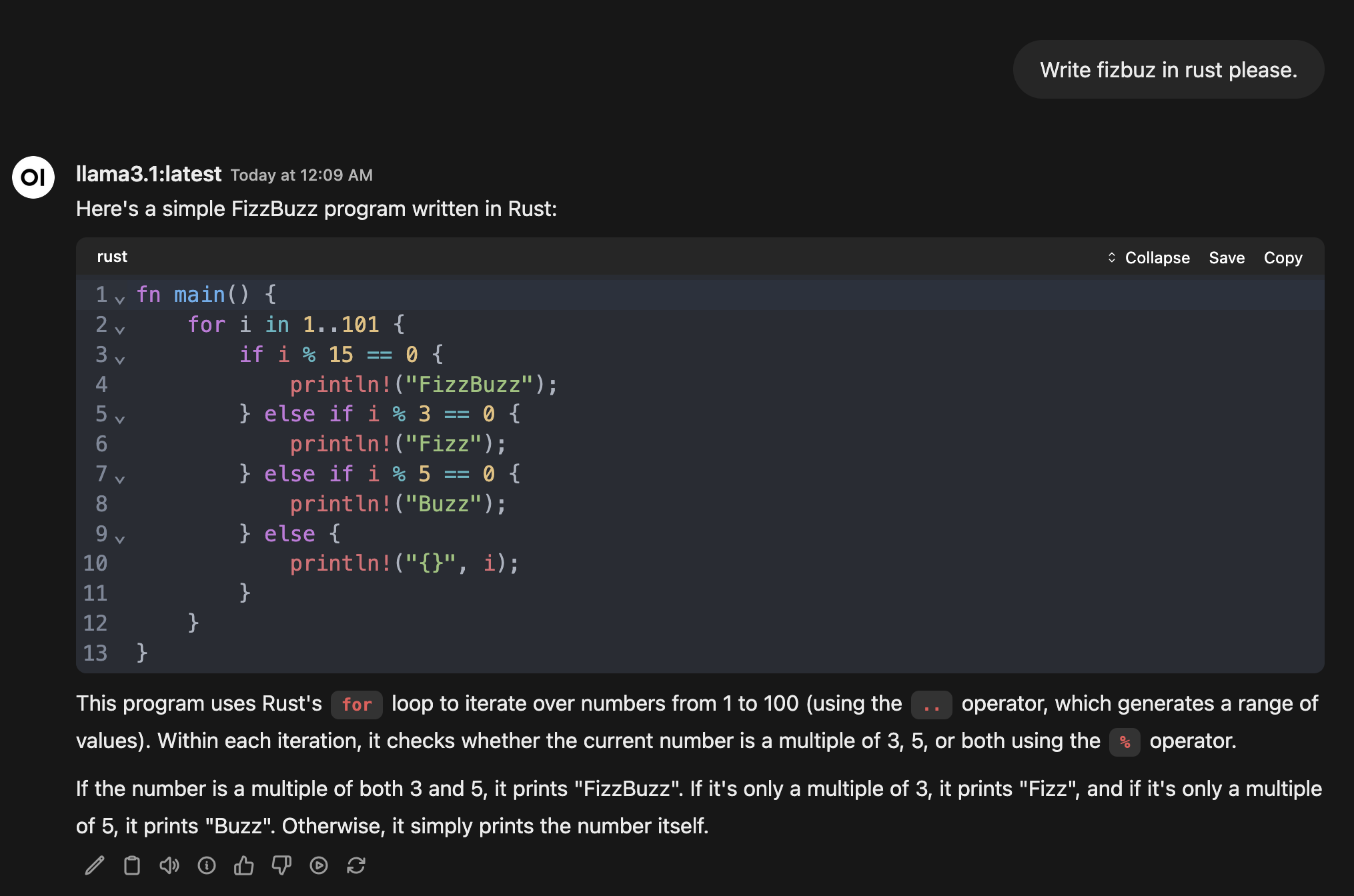
llama3.1 8.0B
Final thoughts
I am truly impressed by the quality of chatting with a computer that runs on a tiny fraction of the large LLMs! It's insane! However, the code quality and ability to write code is somewhat limited. I have tried solving more complex problems using several models (llama3.1, deepseek, codeqwen, command-r7b), but it seems that the small models have lost most of their memory when being shrunk down in manageable sizes for home users. The quantization does not help either. The codes are often more complicated than needed for the problem at hand. And the models repeat themselves even being told explicitly to write the code in a different manner. Hallucination is also of concern.
Claude 4.0 on the other hand (300 B running in the cloud), can have really meaningful conversations about security related topics and best practices. It's like having a conversations with a senior software engineer. I think i need patience. Maybe in a year or two the models are more efficient and more powerful ones can fit my humble rig.